云计算:2. Google云计算
1. Introduction
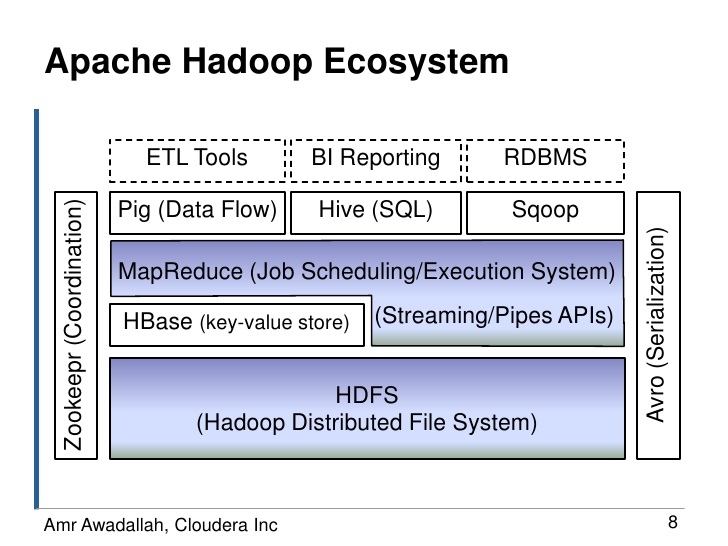
Hadoop实际上就是谷歌三宝的开源实现,Hadoop MapReduce对应Google MapReduce,HBase对应BigTable,HDFS对应GFS,Zookeepr对应Chubby。
- HDFS(或GFS)为上层提供高效的非结构化存储服务;
- HBase(或BigTable)是提供结构化数据服务的分布式数据库;
- Hadoop MapReduce(或Google MapReduce)是一种并行计算的编程模型,用于作业调度。
2. Google文件系统GFS
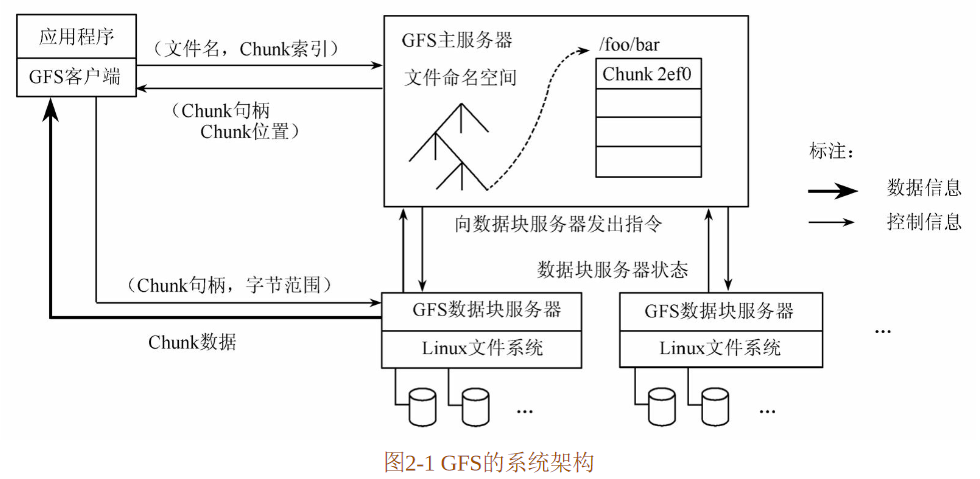
2.1 系统架构
GFS的系统架构如图2-1所示。GFS将整个系统的节点分为三类角色:Client(客户端)、Master(主服务器)和Chunk Server(数据块服务器)。
- Client是GFS提供给应用程序的访问接口,它是一组专用接口,不遵守POSIX规范,以库文件的形式提供。应用程序直接调用这些库函数,并与该库链接在一起。
- Master是GFS的管理节点,在逻辑上只有一个,它保存系统的元数据,负责整个文件系统的管理,是GFS文件系统中的“大脑”。
- Chunk Server负责具体的存储工作。数据以文件的形式存储在Chunk Server上,Chunk Server的个数可以有多个,它的数目直接决定了GFS的规模。GFS将文件按照固定大小进行分块,默认是64MB,每一块称为一个Chunk(数据块),每个Chunk都有一个对应的索引号(Index)。
1. 存取数据
客户端在访问GFS时,首先访问Master节点,获取与之进行交互的Chunk Server信息,然后直接访问这些Chunk Server,完成数据存取工作。
GFS的这种设计方法实现了控制流和数据流的分离。Client与Master之间只有控制流,而无数据流,极大地降低了Master的负载。
Client与Chunk Server之间直接传输数据流,同时由于文件被分成多个Chunk进行分布式存储,Client可以同时访问多个Chunk Server,从而使得整个系统的I/O高度并行,系统整体性能得到提高。
2. 写入数据
使用租约机制来保障在跨多个副本的数据写入中保持顺序一致性,减轻master的负担,有主副本所在的Chunk Server来负责控制流水线的安排。
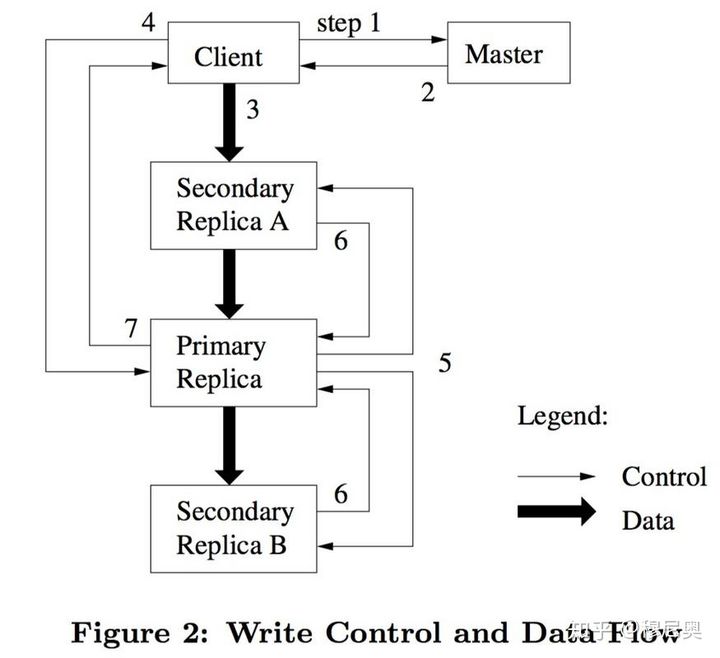
- 客户端向 Master 询问要写的 Chunk 的主副本和其他副本的位置。如果还没有主副本,那么 Master 就通过租约授权一个。
- Master 会给客户端这些位置信息,客户端会将其缓存起来。并且除非主副本不可达或者其租约到期,客户端不会再向 Master 发送请求。
- 客户端将要写的数据推送给各个副本所在的服务器。这里需要注意的一个设计是,GFS 将数据流和控制流进行了解耦,即客户端可以以任何顺序进行数据推送而不用像控制流一样先到主备份再到从备份。这样可以使我们独立优化数据流的推送,甚至可以并行推送;对于大数据块写入是很有好处的,下面章节会详细讨论这个事情。每个 ChunkServer 收到数据后不立即落盘,而是使用 LRU 策略放在缓存里,这也是一个将网络IO和硬盘IO进行解耦的一个操作,一是为了提高效率,一是等待主备份安排写入顺序。
- 当客户端被告知所有副本的数据推送完成后,会向主备份服务器发送写(落盘)请求。主备份所在服务器会把多个并发客户端(如果有的话)的写请求安排一个写入顺序(给每个写请求指定一个序列号),并将其写入前面所说的操作日志。
- 主备份所在服务器将客户端的写请求以及序列号转给其他副本所在服务器。有了这个唯一对应的序列号,所有副本的落盘顺序就能保持一致。
- 所有从备份服务器落完盘后给主备份所在服务器复命。
- 主备份所在服务器回复客户端,如果任何副本写入出现了问题,都会报告给客户端。如果遇到问题,可能有两种:a. 所有副本数据均未落盘。b.部分副本数据落盘成功。对于后者就会出现不一致的状态。客户端的库代码(意味着不用应用代码进行处理)检测到错误后会进行重试,因此在真正成功写入之前,步骤 3~7 可能会重复多次。
3. 分布式事务
两阶段提交:两阶段提交,顾名思义就是要分两步提交。
- prepare: 存在一个负责协调各个本地资源管理器的事务管理器,本地资源管理器一般是由数据库实现,事务管理器在第一阶段的时候询问各个资源管理器是否都就绪?
- commit/rollback: 如果收到每个资源的回复都是 yes,则在第二阶段提交事务,如果其中任意一个资源的回复是 no, 则回滚事务。
4. 特点
- 采用中心服务器模式
- 不缓存数据
- 在用户态下实现
3. 分布式数据处理MapReduce
3.1 编程模型
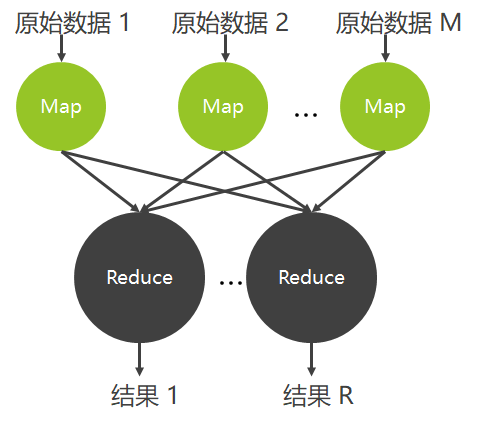
Map函数:对一部分原始数据进行指定的操作。每个Map操作都针对不同的原始数据,因此Map与Map之间是互相独立的,这使得它们可以充分并行化。
Reduce操作:对每个Map所产生的一部分中间结果进行合并操作,每个Reduce所处理的Map中间结果是互不交叉的,所有Reduce产生的最终结果经过简单连接就形成了完整的结果集。
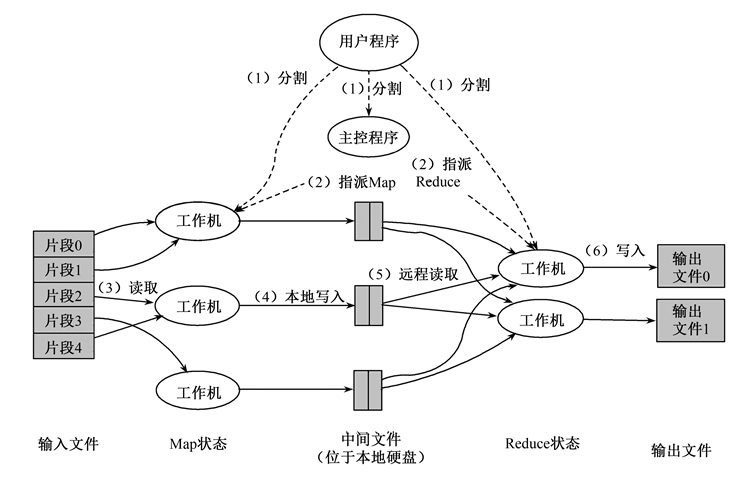
3.2 容错机制
- Master失效
- Master会周期性地设置检查点(checkpoint),并导出Master的数据。一旦某个任务失效,系统就从最近的一个检查点恢复并重新执行。由于只有一个Master在运行,如果Master失效了,则只能终止整个MapReduce程序的运行并重新开始。
- Worker失效
- Master会周期性地给Worker发送ping命令,如果没有Worker的应答,则Master认为Worker失效,终止对这个Worker的任务调度,把失效Worker的任务调度到其他Worker上重新执行。
4. 其它的MapReduce
4.1 Java Stream接口
https://www.runoob.com/java/java8-streams.html
Lambda表达式:函数式编程